
В этой подборке генеративный ИИ для бурения, машинное обучение для поиска sweet-spotов, нейронные сети для интерпретации. FMI
В качестве общественно-полезной нагрузки мне кажется будет познавательным познакомить инженеров с некоторыми исследованиями и практическими кейсами применения ИИ и машинного обучения, которые сейчас обсуждают профессионалы нефтегазовой отрасли.
Генеративный ИИ в бурении

Применение генеративного ИИ в нефтегазе идет медленно, если не сказать, что его просто нет. Поэтому я внимательно слежу за любыми новыми идеями, которые хотя бы отдаленно напоминают реальное применение.
Sabbagh, Lima и Xexeo из Petrobras исследовали возможность использования LLM (больших языковых моделей) для помощи в бурении и ремонте скважин. Они рассмотрели два типа задач:
Задачи вопрос-ответ
Преобразование текста в SQL
Ключевая выгода: повышение продуктивности работников умственного труда
LLMs like GPT-4 enhance productivity in knowledge-intensive tasks, potentially saving significant costs (Dell’Acqua et al. 2023) by increasing productivity of knowledge workers by 12% on average.
If we consider the USD 2.8 billion spent on compensation by a major oil company, 60% of which goes to knowledge workers (USD 1.6 billion), a 12% productivity increase could be viewed as generating an additional USD 204 million worth of output from the same workforce
Боль
Изучение суточных отчетов по бурению — унылое занятие, особенно в если нужно поискать что-то что произошло пару месяцев назад и ты не помнишь на какой конкретно скважине это случилось. Но эти отчеты содержат нюансы, критически важные для текущих операций: от проблем при строительстве скважин до потенциальных будущих осложнений при их ремонте.

Результаты
Одиночные и многоагентные системы не только справились с задачами, но и показали достойный уровень достоверности. Многоагентные системы лучше справились с Q&A-задачами, а одиночный агент — с задачами Text-to-SQL. Отдельное внимание уделено стоимости вычислений, так как многоагентные системы дороже в использовании.
Мета-исследование по использованию машинного обучения в поиске sweet-spotов для скважин

Khanjar делал мета-анализ научных работ по использованию машинного обучения для поиска «sweet spots» в нефтегазовых месторождениях и собрал разные подходы к этой проблеме.
Боль
Sweet-spot — это зоны в пласте, где дебит скважины значительно выше среднего. Их точная локализация критически важна при проектировании новых и расширении существующих буровых программ. В этом мета-анализе сравниваются разные алгоритмы и их применимость.
Результаты
Автор выделил лучшие практики по сбору, подготовке и обработке данных. Отдельно проведено исследование значимых признаков, влияющих на точность моделей.
Важно отметить, что не все исследования дали статистически значимые результаты. Но многие показали, что задача поиска «sweet spots» может быть решена методами машинного обучения, как для новых, так и для зрелых месторождений.
Замена традиционного моделирования на ML для оценки остаточной нефтенасыщенности пород

Боль
Традиционное моделирование в нефтегазе:
Дорого
Долго
Склонно к ошибкам (из-за сложности процессов и несовершенства данных)
Глубокое обучение, конечно, менее объяснимо, но зато даёт огромный выигрыш в скорости после обучения модели.
Rizsk et al. предложили гибридный подход: сочетание моделирования и глубокого обучения.
За счет этого мы снижаем стоимость процесса моделирования и увеличиваем скорость
Минутка инженерного восхищения
Как негеолога, больше всего меня зацепил сам метод создания модели керна. Из множества КТ-сканов формируется воксельная 3D-модель породы.

Затем извлекаются признаки, добавляются другие данные, и на их основе обучается модель. Настоятельно рекомендую ознакомиться с этой работой — в ней можно найти массу идей для других направлений моделирования.
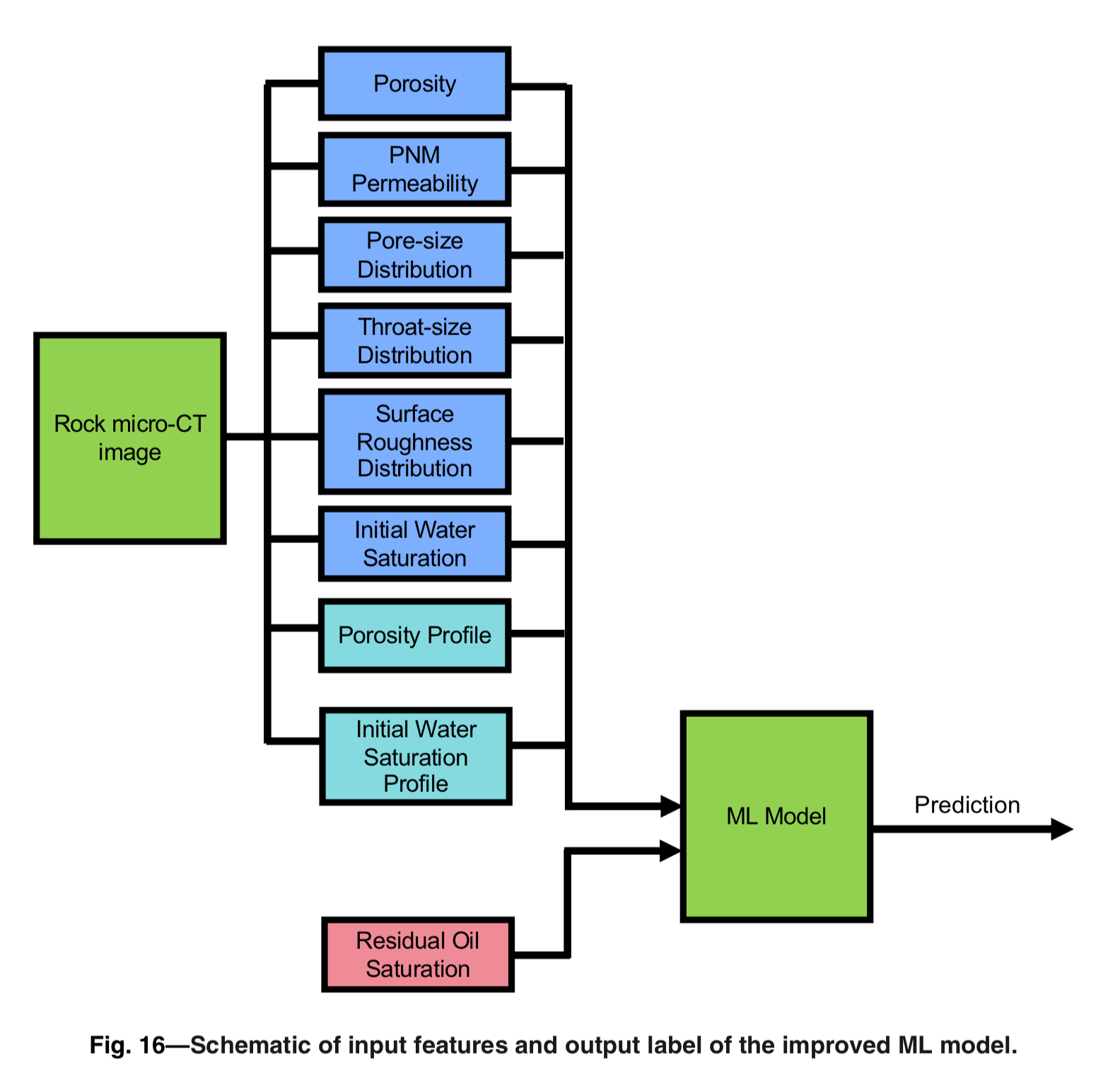
Компьютерное зрения для интерпретации FMI скважин

Боль
Интерпретация FMI (formation microimager) логов:
Долгая
Рутинная
Склонная к ошибкам
Но при этом крайне важна для характеристики пласта. Если ваш фонд охвачен FMI — то можно получить гораздо более точное представление о трещинах в породе, о том как сформировалась залежь и о том как будет происходить добыча. Все это вкладывается в гидродинамическую модель. Но процесс очень сложен и зависит от конкретных инженеров, которые FMI интерпретируют.
Решение
Создание размеченного датасета для обучения нейросетей с целью автоматической интерпретации FMI-логов. Автоматическая идентификация:
Пластовых границ
Трещин
Минералогических изменений
Разломов и прочего
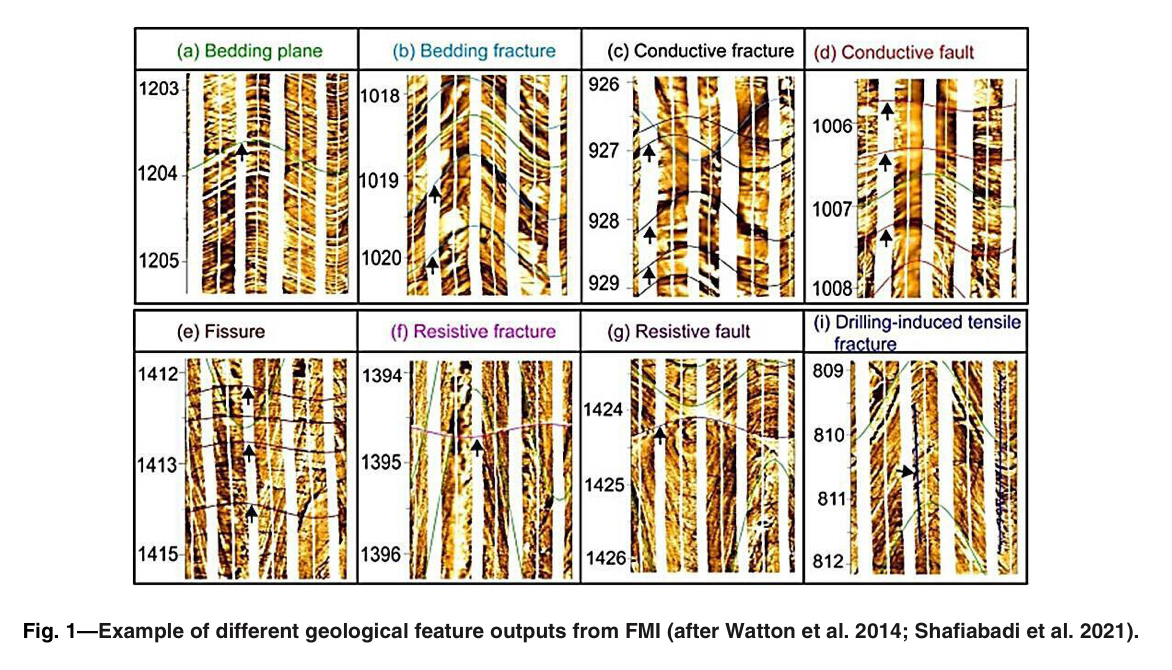
Результаты
Всем, кто работал с computer vision, то методология знакома. Основная работа — разметка данных.
В данном случае инженеры вручную разметили 2500 образцов (по 50 образцов на 50 различных признаков). Дальше все просто: извлечение признаков + нейросеть (например, на базе ImageNet).
Отличный пример того, как машинное обучение масштабирует крайне ограниченный ресурс — время высококвалифицированных инженеров.
Добавить комментарий